추천 시스템이란?
추천 시스템은 그 이름에서 짐작할 수 있듯이 관심을 가질만한 정보를 추천해주는 것인데요.
검색 서비스와 비슷하면서도 다른 점이 있습니다.
검색 서비스는 사용자가 스스로 원하는 바를 알고 있고, 사용자가 요구한 후 작동하지만
추천 서비스는 사용자가 스스로 원하는 바를 알지 못하고, 사용자가 요구하기 전에 작동합니다!
즉, 추천 서비스는 사용자가 정보를 수집하고 찾는 시간을 줄여주는 것이 가장 큰 목적이라고 할 수 있습니다.
추천의 간략한 원리
추천 서비스는 사용자(User)와 상품(Item)으로 구성되어 있고, User와 Item을 프로파일링(Profiling) 해야합니다.
User의 경우
사용자ID, 나이, 성별, 지역, 학력 등 개인 신상정보나
쿠키, 인터넷 주소, 웹페이지 방문 기록, 클릭 패턴 등의 데이터를 이용하여 프로파일링이 가능합니다.
이런 데이터를 수집하기 위해서 두가지 방법을 이용할 수 있는데요.
직접적(Explict) 방법으로 설문조사, 평가, 피드백 등이 있으며
간접적(Implict) 방법으로는 웹페이지 체류시간, 클릭 패턴, 검색 로그 분석 방법이 있습니다.
Item의 경우
플랫폼마다 그 종류가 다른데요,
예를 들어 은행의 경우 금융 상품 또는 서비스 넷플릭스의 경우 영상 콘텐츠가 되겠죠?ㅎㅎ
이렇게 잘 프로파일링 된 User/Item 정보를 바탕으로 선호도를 점수화 하는 것이 추천이라고 할 수 있습니다!
추천을 왜, 어디에 써야해?
추천을 통해서 얻을 수 있는 장점으로는
- 더 많은 아이템을 판매할 수 있고
- 더 다양한 아이템을 판매할 수 있고
- 소비자 만족도가 증가하고
- 충성 고객이 증가하고
- 고객의 니즈를 파악할 수 있다는 것
등이 있습니다.
이에 넷플릭스는 콘텐츠 추천에, 인스타그램은 팔로우 추천에, 쿠팡은 상품 추천에 추천 시스템을 사용하고 있습니다 :)
추천 시스템의 데이터 종류
Item
추천할 항목이라고도 할 수 있고요, 가치와 데이터의 복잡함에 따라 구분이 가능합니다.
낮은 복잡도를 가지는 대표적인 Item은 뉴스, 책, 영화 등이 있고
높은 복잡도를 가지는 대표적인 Item은 금융상품(ㅠㅠ), 직업, 여행 등이 있습니다.
User
여러 목적과 특징을 가지는 집단으로 행동 패턴 등으로 모델링이 가능합니다.
위에 살짝 언급한 인스타그램의 팔로우 추천 예시처럼 사회적 요인 또한 활용이 가능합니다.
Transaction
User와 Item간의 상호작용 입니다. User가 인터넷에 남긴 로그에서 중요한 정보를 추출한 것입니다 ㅎㅎ
예를 들면 해시태그, 평점 그 외에도 Implict한 정보 모두 활용 가능합니다.
추천 알고리즘이 풀고자 하는 문제
추천 알고리즘이 풀고자 하는 문제는 크게 두 가지로 구분할 수 있는데요.
첫 번째는 랭킹 문제입니다.
이름에서 짐작할 수 있듯이, 특정 User가 좋아할만한 Top-K Item 또는 특정 Item을 좋아할만한 Top-K User를 찾는 문제로
순서가 중요하게 때문에 평점이나 점수를 정확하게 예측 할 필요는 없습니다!
두 번째는 예측 문제입니다.
평점(or 점수)를 예측하는 게 목적으로 User-Item 행렬을 채우는 문제를 푸는 것 입니다.
추천 알고리즘의 종류
콘텐츠 기반(Contents-based Recommender System)
사용자가 과거에 좋아했던 아이템을 파악하고, 그 아이템과 비슷한 아이템을 추천하는 방법입니다.
예를 들어, 과거에 스파이더 맨 영화에 평점 4.5를 준 사용자에겐 타이타닉 보다는 캡틴 마블을 추천하는 식입니다.
협업필터링(Collaborative Filtering)
비슷한 성향 또는 취향을 가지는 다른 유저가 좋아한 아이템을 현재 유저에게 추천하는 방식으로 간단하면서도 수준 높은 정확도를 보여줍니다.
예를 들어, 스파이더맨에 평점 4.5를 준 두 명(A, B)의 유저가 있다면 유저 A가 과거에 좋아했던 캡틴 마블을 유저 B에게 추천하는 식입니다.
Hybrid Recommender System
콘텐츠 기반 추천과 협업 필터링 추천의 장, 단점을 상호 보완한 방법입니다.
협업 필터링의 경우 새로운 아이템에 대한 추천이 부족한데 이를 콘텐츠 기반 기법이 보완해 줄 수 있습니다.
기타 추천 알고리즘
- Context-based Recommendation : 위치 기반 또는 시간의 흐름에 따른 추천
- Community-based Recommendation : 사용자의 친구 또는 속한 커뮤니티의 선호도를 바탕으로 추천 (예, SNS등의 뉴스 피드)
- Knowledge-based Recommendation : (Constraint based) 정해진 규칙을 바탕으로 또는 (Case based) 사용자 니즈와 해결책 중 가장 적합한 것을 골라서 추천
추천 시스템의 한계
좋아 보이기만 하는 추천 시스템이지만, 한계점이 존재합니다.
Scalabillity
학습/분석에 사용한 데이터와 실전 데이터는 전혀 다를 가능성이 높습니다.
예를 들어, 코로나로 인한 마스크 구매 급등 현상과 같이 실제 서비스 상황은 항상 다를 수 있습니다.
Procative Recommender System
가장 처음 언급했듯 추천 서비스란 사전 요청이 없어도 먼저 제공이 되어야 하는데요, 끊임없이 좋은 정보를 추천해 주는 것은 매우 어려운 문제입니다.
Cold-Start Problem
새로 생긴 Item, 신규 가입 User등의 경우 추천 서비스를 위한 데이터 부족합니다.
Privacy preserving Recommender System
개인 정보가 가장 중요하지만 사용하기 어렵습니다.
Mobile devices and Usage Contexts
위치 기반 또는 개인적 환경에 맞게 다른 콘텐츠를 추천해 줄 수 있어야 합니다.
Long-term and Short-term user preference
추천 받고 싶은 아이템이 지금도 관심 있는 지 파악하기가 어렵습니다.
Generic User models and Cross Domain Recommender System
하나의 모델을 여러가지 데이터에 적용하기 어렵습니다.
비슷한 도메인의 데이터를 활용한다고 해도 동일한 성능의 추천 시스템을 기대하기 어렵습니다.
Starvation and Diversity
추천의 경우 방대한 양의 데이터를 사용하고 있는데, 필요한 컴퓨팅 자원을 끊임없이 가져오는 것 역시 아주 어렵습니다.
Long-Tail Economy
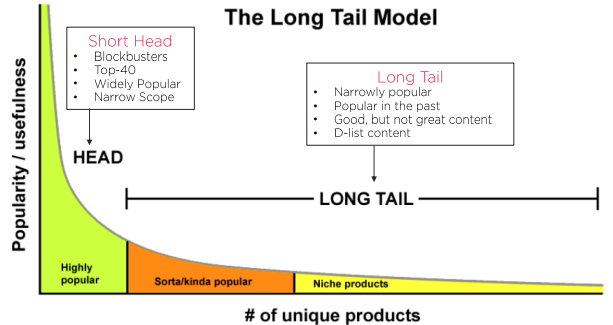
관측된 데이터는 아주 일부고, 관측되지 않은 데이터가 대부분이라는 뜻인데요!
이런 현상으로 인해 일부 데이터만 이용하게 된다면 굉장히 쏠린 결과가 나올 수도 있습니다.
그럼 추천하지 마요?
아닙니다! 이런 한계점들이 있지만, 그렇기 때문에 추천에는 정답이 없습니다!
로맨스 영화만 좋아하던 유저에게 액션 영화를 추천을 통해 유저가 새로운 재미를 발견할 수도 있고,
감자튀김을 좋아하는 유저에게 햄버거를 추천해줬지만, 비건이라 햄버거를 안 먹을 수도 있습니다!
따라서 추천 시스템에서는 최대한 다양한 시도를 해보는 게 좋은 것 같습니다 :)