Chap02. End-to-End Machine Learning Project
이 장에서는 아래와 같은 주요 단계를 거치며 메인 프로젝트를 진행합니다.
- Look at the big picture.
- Get the data.
- Discover and visualize the data to gain insights.
- Prepare the data for Mahine Learning algorithms.
- Select a model and train it.
- Fine-tune your model.
- Present your solution.
- Launch, monitor, and maintain your system.
Working with Real Data
머신 러닝을 배울 대는 실제 데이터로 연습해 보는 것이 가장 좋습니다. 아래 책에서 소개하는 몇개의 오픈 데이터 셋 사이트와, 우리나라 공공 데이터 사이트들의 링크가 있습니다.
- 책에서 소개하는 사이트
- 우리나라 공공 데이터 사이트
이 장에서는 StatLib repository의 California Hosing Prices 데이터 셋을 이용합니다. 이 데이터 셋은 1990 California 센서스 데이터에 기반을 두고 있으며, 범주형 변수를 추가하고 몇개의 변수를 삭제할 것입니다.
Look at the Big Picture
이제 California 센서스 데이터를 이용하여 California의 집 값에 대한 모형을 구축할 것 입니다. 이 데이터는 인구 수, 중위 소득, 중위 집 값 등에 대한 값을 각 block group에 대해 가지고 있습니다. block group을 줄여서 구역이라고 하겠습니다.
모델은 데이터를 학습해서 모든 변수들이 주어져 있을 때, 어느 구역에서나 중위 집 값을 예측할 수 있어야 합니다.
Frame the Problem
- 학습 방법: 전형적인 지도 학습이며 특히 다항 회귀 분석을 통해 값을 예측할 수 있습니다.
- 데이터가 연속적으로 시스템에 들어오지 않으므로, 데이터를 빠르게 변화시켜 조정할 필요가 없습니다.
- 데이터가 메모리에 저장될 만큼 충분히 작으므로, plain batch learning으로 충분합니다.
Select a Performance Measure
회귀 문제의 대표적인 성능 지표는 Root Mean Square Error (RMSE)와 Mean Absolute Error (MAE)가 있습니다.
- RMSE(X, h) = \(\sqrt{ \frac{1}{m} \sum_{i = 1}^{m} (h(x^{(i)} - y^{(i)} )^2 }\)
- MAE(X, h) = \(\frac{1}{m} \sum_{i = 1}^{m} \mid h(x^{(i)}) - y^{(i)} \mid\)
RMSE와 MAE 모두 예측 벡터와 타겟 벡터, 두 벡터 사이의 거리를 측정하는 방법입니다. 다양한 거리 측정치 또는 norms가 가능합니다.
- RMSE는 Euclidean norm에 해당합니다. \(l_2\) norm이라고도 불리며 \(\| \cdot \|_2\)으로 표기합니다.
- MAE는 \(l_1\) norm에 해당하며 \(\| \cdot \|_1\)로 표기합니다.
- 일반적으로 n개의 원소가 있는 벡터 v의 \(l_k\) norm은 \(\| v\|_k = (\lvert v_0 \rvert ^k + \lvert v_1 \rvert ^k + \cdots + \lvert v_n\rvert ^k)^{\frac{1}{k}}\)로 정의합니다. \(l_0\)는 0이 아닌 원소의 갯수이며, \(l_\infty\)는 절대값의 최댓값입니다.
- norm index가 클 수록 큰 값에 집중하며 작은 값을 무시합니다. 이는 RMSE가 MAE보다 이상치에 민감한 이유이기도 합니다. 하지만 이상치가 지수적으로 드물다면 RMSE의 성능이 좋기때문에 보편적으로 선호됩니다.
Check the Assumptions
마지막으로, 가정을 확인해 보는 것은 매우 좋은 관행입니다. 이를 통해 심각한 문제를 일찍 확인할 수 있습니다. 예를 들어, 구역 가격이 연속형이 아닌 범주형이였다면 우리는 회귀분석을 시행할 게 아니라 분류 문제를 수행해야 합니다.
Get the Data
여기서 분석할 데이터는 Hands on Machine Learning 깃허브 에서 가져올 수 있습니다.
Create the Workspace
교재에서는 파이썬을 설치하고 주피터 노트북을 이용하여 분석 환경을 만들었지만, 여기서는 google Colab을 사용하기로 합니다.
from google.colab import drive
drive.mount('/content/drive')Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
# Import modules
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pdDownload the Data
Hands on Machine Learning 깃허브를 통하여 데이터 파일과 주피터 노트북 코드를 다운받을 수 있습니다. 여기서는 교재와 달리 데이터를 다운 받아 구글 드라이브에 저장 후 불러와서 사용하였습니다.
Take a Quick Look at the Data Structure
head() 를 이용하여 데이터 프레임의 5개 행을 확인할 수 있습니다.
housing = pd.read_csv("/content/drive/My Drive/colab/data/housing.csv")
housing.head()| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
각 행은 하나의 구역을 나타내며, 총 10개의 변수(경도, 위도, 주택 중위 연식, 총 방, 총 침실, 인구, 가정, 중위 소득, 중위 집 값, 해안 근접)가 있습니다.
info()를 이용하여 행 개수, 변수 타입, 결측치의 개수 등의 데이터 설명을 확인할 수 있습니다.
housing.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
total_bedrooms 20433 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
데이터에는 20,640개의 행이 있습니다. 여기서 total_bedrooms 변수는 20433개의 non-null 데이터가 있는데 이를 통해 207개의 구역에 대한 결측치가 존재한다는 것을 알 수 있습니다. 이에 대한 처리는 나중에 할 것 입니다.
ocean_proximity변수만 object타입인 것을 확인할 수 있습니다. head()를 통해서 데이터를 확인해 본 결과 문자형, 범주형 변수 인 것을 확인할 수 있었습니다. 어떤 범주가 얼마나 많이 있는지는 value_counts()를 통해서 확인할 수 있습니다. (R에서 table과 유사한 기능)
housing['ocean_proximity'].value_counts()<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
describe()는 숫자형 변수들에 대한 summary를 보여주며, null값은 무시됩니다. (R에서 summary와 유사한 기능)
housing.describe()| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
데이터 특성을 확인하는 다른 방법은 hist()를 이용해서 각 숫자형 변수에 대한 히스토그램을 그려보는 것입니다. 데이터 전체에 한번에 적용해도 됩니다.
housing.hist(bins = 50, figsize = (20, 15))
plt.show()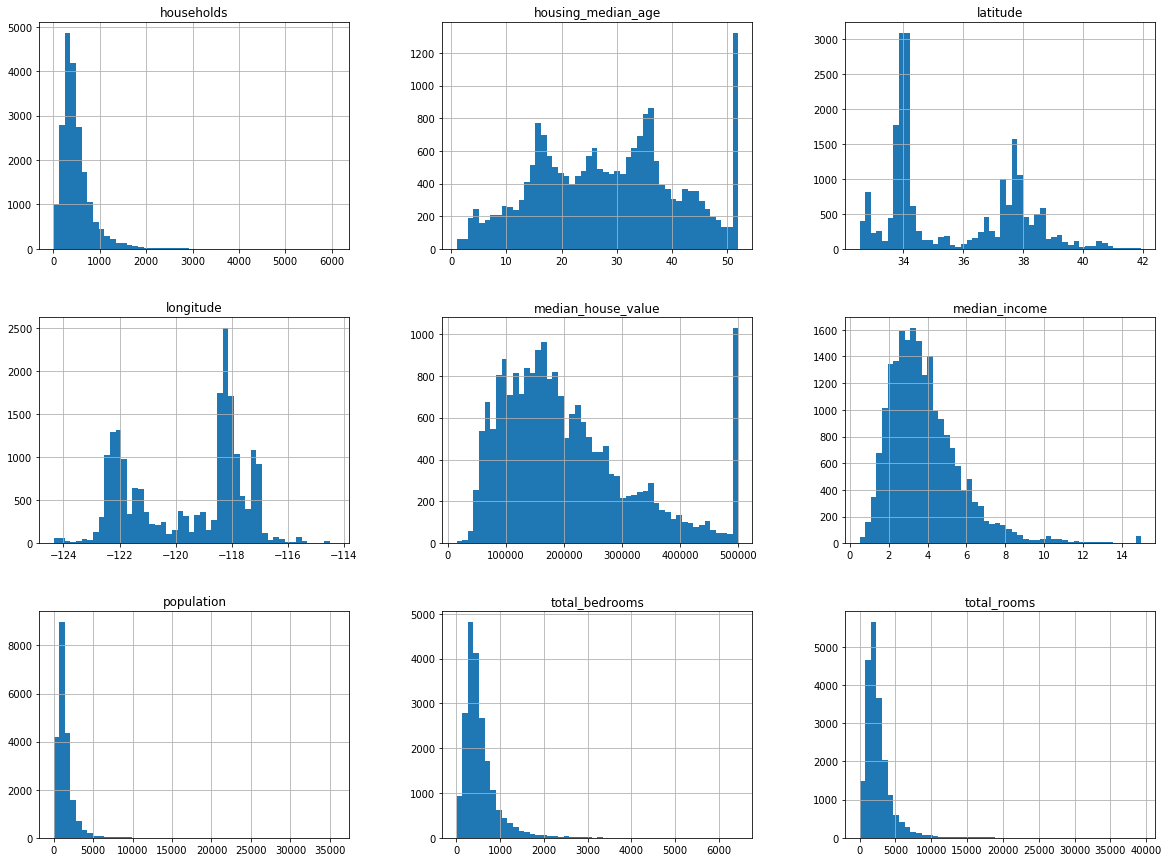
히스토그램을 통해 다음과 같은 사실을 알 수 있습니다.
- 중위 소득이 USD 단위가 아닌 것을 확인 할 수 있고, 15를 초과하는 중위 소득은 15로, 0.5 미만인 중위 소득은 0.5로 처리된 것을 확인할 수 있습니다. 숫자는 10000 달러 단위로 나타내져 있습니다.
- 주택 중위 연식과 중위 집 값 역시 범위가 제한되어 있음을 확인할 수 있습니다. 중위 집 값은 타겟 변수이기 때문에 머신 러닝 알고리즘이 제한된 값을 넘어서 학습을 할 수 없기 때문에 문제가 있을 수 있습니다. 만약 $500,000을 넘어선 값을 예측해야 한다면 주로 두 가지 선택 방안이 있습니다:
- 제한된 값들에 대한 적절한 라벨을 찾는다.
- 훈련 셋과 테스트 셋에서 이 구역들을 제외한다.
- 변수들이 매우 다른 스케일을 가지고 있습니다.
- 많은 히스토그램이 꼬리가 두꺼우며, 오른쪽으로 꼬리가 긴 분포를 갖고 있습니다. 추후에 종 모양의 분포를 갖도록 변환을 할 것 입니다.
Create a Test set
이 단계에서 데이터를 일부러 나누는 것을 이상하다 생각할수도 있습니다. 하지만, 우리의 뇌는 놀라운 패턴 감지 시스템인데, 과적합\(^{overfitting}\)이 일어나기 쉽습니다: 테스트 셋을 보고, 겉보기에 흥미로운 패턴에 속아 특정한 종류의 머신 러닝 모델을 선택할 수도 있습니다. 이런 테스트 셋을 사용하여 일반화 오류를 추정할 때 예상치가 너무 낙관적이어서 시스템이 기대만큼 작동하지 않을 것입니다. 이것을 데이터 스누핑 편향\(^{data~ snooping~ bias}\) 이라고 합니다.
이론적으로 테스트 셋을 만드는 것은 매우 간단합니다: 보통 데이터 셋의 20%정도의 행을 무작위로 선택하고, 그 셋을 따로 떼어놓습니다.
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data)*test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]train_set, test_set = split_train_test(housing, 0.2)len(train_set)16512
len(test_set)4128
위 코드는 실행할 때 마다 다른 테스트 셋을 반환합니다. 이를 해결하기 위해서는, 처음 얻은 테스트 셋을 저장해놓는 방법이 있고, 다른 방법으로는 random number generator’s seed (e.g., np.random.seed(42)) 코드를 추가하는 방법이 있습니다. (R에서 set.seed와 비슷한 기능)
하지만 위 두 방법 모두 업데이트 된 데이터 세트에 대해서는 적용되지 않습니다. 일반적인 해결책은 각 인스턴스의 식별자를 이용하여 테스트 셋에 들어가는지 여부를 확인하는 것입니다. 예를 들어 각 인스턴스 식별자의 해시를 계산하여 해시가 최대 해시 값의 20%보다 낮거나 같으면 해당 인스턴스를 테스트 셋에 넣을 수 있습니다. 이렇게 하면 데이터 셋을 새로 고치는 경우에도 여러 번의 실행에서 테스트 셋가 일관성을 유지할 수 있습니다. 새 테스트 셋은 새 인스턴스의 20%를 포함하지만 이전에 교육 세트에 있었던 인스턴스는 포함하지 않습니다. 다음과 같이 구현할 수 있습니다.
from zlib import crc32
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[-in_test_set], data.loc[in_test_set]housing 데이터 셋에는 식별자 열이 없기 때문에 행 인덱스를 ID로 사용합니다.
housing_with_id = housing.reset_index() # 'index'열 추가train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, 'index')housing_with_id.head()| index | longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
만약 행 인덱스를 식별자로 사용한다면, 세로운 데이터를 기존 데이터 셋의 끝에 붙여야 하고, 행을 삭제하면 안된다. 그럴 수 없다면, 가장 안전한 열을 식별자로 설정하면 된다. 예를 들어, 지역의 위 경도는 오랜 세월동안 변함없이 사용되었으므로, 둘을 결합하여 ID로 사용할 수 있다.
housing_with_id['id'] = housing['longitude'] * 1000 + housing['latitude']
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, 'id')Scikit-Learn은 데이터를 나누는 다양한 함수를 제공해줍니다. 가장 간단한 함수는 train_test_split입니다. 이 함수는 random_state인자를 통해 데이터를 항상 같은 인덱스로 나눌 수 있습니다.
from sklearn.model_selection import train_test_splittrain_set, test_set = train_test_split(housing, test_size = 0.2, random_state = 42)지금까지 완전 무작위 샘플링 방법에 대해 알아보았습니다. 이는 데이터셋이 충분히 크면 괜찮지만, 그렇지 않다면 심각한 샘플링 편향을 가져올 수 있습니다. 만약 범주형 변수가 있고, 범주의 비율에 맞춰서 샘플링을 해야한다면 Scikit-Learn의 stratifiedShuffleSplit 클래스를 사용하면 됩니다.
이를 위해 먼저 중위 소득을 이용해서 범주형 변수를 만들겠습니다. 아래와 같은 코드를 사용해서 범주형 변수를 만들 수 있으며, 범주 1에 속하는 범위는 0 초과 ~ 1.5 이하, 범주 2에 속하는 범위는 1.5 초과 ~ 3이하 입니다.
housing['income_cat'] = pd.cut(housing['median_income'],
bins = [0., 1.5, 3.0, 4.5, 6., np.inf],
labels = [1, 2, 3, 4, 5])housing['income_cat'].hist()
plt.show()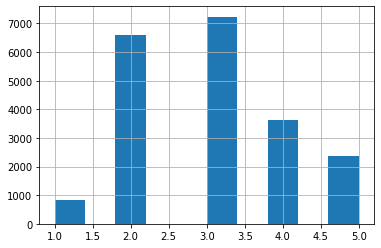
from sklearn.model_selection import StratifiedShuffleSplitsplit = StratifiedShuffleSplit(n_splits = 1, test_size = 0.2, random_state = 42)
for train_index, test_index in split.split(housing, housing['income_cat']):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]아래와 같은 코드를 통해 단순 무작위 추출과 층화 추출의 표본 비율을 비교해 볼 수 있습니다. 표에서 확인할 수 있듯이 층화 추출을 통해 뽑은 샘플은 전체 데이터 셋과 거의 동일한 범주 비율을 가지고 있지만, 단순 무작위 추출을 통해 뽑은 샘플은 매우 편향되어 있습니다.
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100이제 income_cat을 제거해서 원래 데이터로 돌려놓겠습니다.
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis = 1, inplace = True)Discover and Visualize the Data to Gain Insights
여기서는 트레이닝 셋만 이용하여 데이터를 살펴보겠습니다.
housing = strat_train_set.copy()Visualizing Geographical Data
위 경도 데이터가 있으므로 산점도를 이용하여 데이터를 시각화 해보겠습니다.
housing.plot(kind = "scatter", x = 'longitude', y = 'latitude')
plt.show()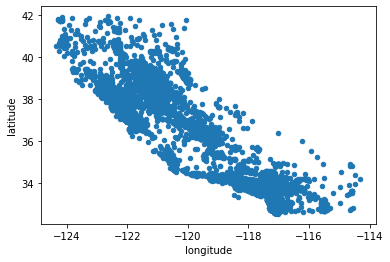
점들이 겹쳐있어서 데이터가 얼마나 있는지 확인하기 어려우므로, 투명도를 조정하는 인자인 alpha를 0.1로 해서 데이터를 살펴보겠습니다.
housing.plot(kind = 'scatter', x = 'longitude', y = 'latitude', alpha = 0.1)
plt.show()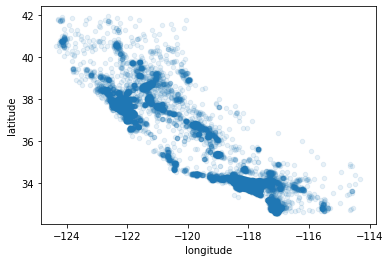
이제 밀도가 높은 지역을 쉽게 확인할 수 있습니다! Los Angeles와 San Diego, Sacramento, Fresco 주위에 많은 데이터가 있는 것을 확인할 수 있습니다.
이제 집 값도 살펴보겠습니다. 각 원의 반지름은 그 지역의 인구 수 (s), 색은 가격 (c)을 나타냅니다. 낮은 값은 파란색, 높은 값은 빨간색으로 표시되는 jet이라고 불리는 컬러 맵을 사용하겠습니다 (cmap).
housing.plot(kind = 'scatter', x = 'longitude', y = 'latitude', alpha = 0.4,
s = housing['population']/100, label = 'population', figsize = (10, 7),
c = housing['median_house_value'], cmap = plt.get_cmap('jet'), colorbar = True)
plt.legend()
plt.show()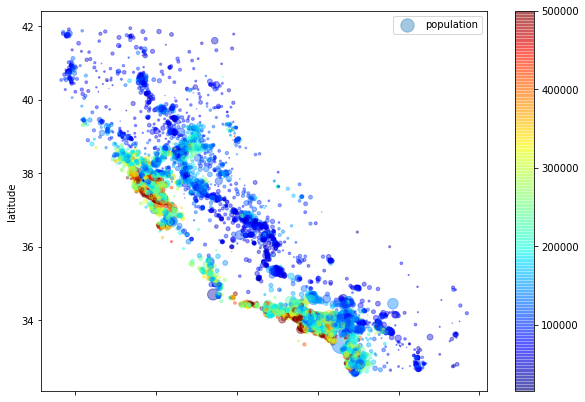
위 그림을 통해 이미 알고 있듯이 집값이 지역(예, 해변 근처) 및 인구 밀도와 밀접한 관련이 있는 모습을 확인할 수 있습니다. 클러스터링 알고리즘을 사용하여 주 클러스터를 찾고 클러스터의 중심과의 유사도를 측정한 새 변수를 추가하는 게 유용할 수 있습니다. 해변 근처 변수 또한 유용할 수 있지만, 캘리포니아 북부 지역에서는 해변 근처의 집값이 높지 않기 때문에 그리 간단한 문제가 아닙니다.
위 그림을 지도위에 그려보겠습니다.
import os
import matplotlib.image as mpimg
import urllib# Download the California image
images_path = os.path.join('.', "images", "end_to_end_project")
os.makedirs(images_path, exist_ok=True)
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
filename = "california.png"
print("Downloading", filename)
url = DOWNLOAD_ROOT + "images/end_to_end_project/" + filename
urllib.request.urlretrieve(url, os.path.join(images_path, filename))Downloading california.png
('./images/end_to_end_project/california.png',
<http.client.HTTPMessage at 0x7f1a5f5d6cc0>)
california_img=mpimg.imread(os.path.join(images_path, filename))
ax = housing.plot(kind="scatter", x="longitude", y="latitude", figsize=(10,7),
s=housing['population']/100, label="Population",
c=housing["median_house_value"], cmap=plt.get_cmap("jet"),
colorbar=False, alpha=0.4,
)
plt.imshow(california_img, extent=[-124.55, -113.80, 32.45, 42.05], alpha=0.5,
cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude", fontsize=14)
plt.xlabel("Longitude", fontsize=14)
prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(), prices.max(), 11)
cbar = plt.colorbar()
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize=14)
cbar.set_label('Median House Value', fontsize=16)
plt.legend(fontsize=16)
plt.show()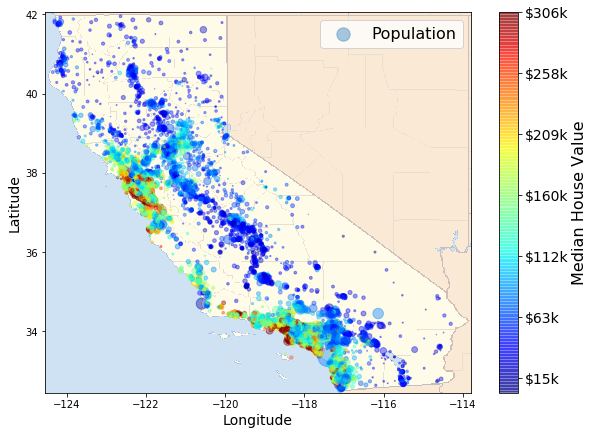
Looking for Correlations
corr_matrix = housing.corr()
corr_matrix['median_house_value'].sort_values(ascending = False)median_house_value 1.000000
median_income 0.687160
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population -0.026920
longitude -0.047432
latitude -0.142724
Name: median_house_value, dtype: float64
변수들 사이의 상관관계를 확인하는 또다른 방법은 Pandas의 scatter_matrix 함수를 사용하는 것입니다. 이 함수는 숫자형 변수들 끼리의 산점도를 그려줍니다. 대각원소는 그 변수의 히스토그램이 그려집니다.
from pandas.plotting import scatter_matrixattributes = ['median_house_value', 'median_income', 'total_rooms', 'housing_median_age']
scatter_matrix(housing[attributes], figsize = (12, 8))
plt.show()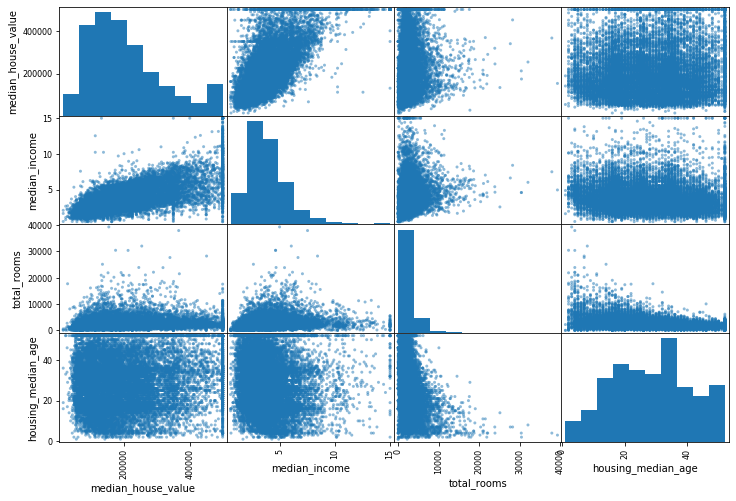
중위 집 값을 예측하는 가장 주요한 특성은 중위 소득입니다. 따라서, 그들의 상관 관계 그림을 확대해보겠습니다.
housing.plot(kind = 'scatter', x = 'median_income', y = 'median_house_value', alpha = 0.1)
plt.show()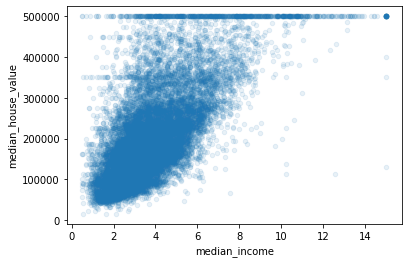
위 그림을 통해 몇가지 특징을 확인할 수 있습니다. 첫번째로, 상관관계가 매우 강해 보입니다. 두번째로, 중위 집 값의 상한값이 낮아서 $500,000에서 수평선이 나타나는 것을 확인할 수 있습니다. 또한 몇개의 수평선을 더 확인할 수 있으며, 해당 지역을 제거하여 알고리즘이 이런 이상 현상을 학습할 수 없도록 할 수 있습니다.
Experimenting with Attribute Combinations
이전 섹션을 통해서 우리는 머신 러닝 알고리즘을 적용하기 전에 지우고 싶은 데이터나, 흥미로운 상관관계 또는 변환이 필요해보이는 꼬리가 두꺼운 분포를 띄는 변수들을 확인해 봤습니다.
마지막으로 우리는 다양한 변수들의 결합을 시도해 볼 겁니다. 예를들어, 지역 내 총 방의 개수는 그 지역에 얼마나 많은 가구가 있는 지 알 수 없다면 그리 유용하지 않습니다. 비슷하게 총 침실의 개수도 그 자체로는 유용하지 않습니다. 따라서 새로운 변수를 만들어 보겠습니다.
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]corr_matrix = housing.corr()
corr_matrix['median_house_value'].sort_values(ascending = False)median_house_value 1.000000
median_income 0.687160
rooms_per_household 0.146285
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population_per_household -0.021985
population -0.026920
longitude -0.047432
latitude -0.142724
bedrooms_per_room -0.259984
Name: median_house_value, dtype: float64
나쁘지 않은 결과입니다! bedrooms_per_room변수는 총 방 개수나 총 침실 개수보다 중위 집값과 더 높은 상관관계를 갖고있습니다. 낮은 침실/방 비율을 가진 집이 더 비싼 경향을 갖는 것으로 보입니다. 가구 당 방 개수 또한 총 방 개수보다 더 유용합니다.
Prepare the Data for Machine Learning Alogrithms
이제 머신러닝 알고리즘을 위한 데이터를 준비해야 할 때입니다. 이 작업을 수동으로 수행하는 대신 몇 가지 이유로 함수로 작성해야 합니다.
- 어느 데이터 셋에서든 쉽게 변환할 수 있게 해줍니다.
- 향후 프로젝트에서 재 사용할 수 있는 변환 함수 라이브러리를 구축할 수 있게 됩니다.
- 알고리즘에 적용해 보기 전에 함수를 이용해서 새 데이터를 변환할 수 있습니다.
- 다양한 변환을 쉽게 시도해 볼 수 있게 해주며, 어떤 조합의 변환이 가장 효율적인지 확인할 수 있습니다.
하지만 먼저 트레이닝 셋으로 돌아가서, predictiors와 labels에 같은 변환을 적용할 수 없으므로, 이 둘을 분리하겠습니다.
housing = strat_train_set.drop('median_house_value', axis = 1)
housing_labels = strat_train_set['median_house_value'].copy()Data Cleaning
대부분의 머신러닝 알고리즘은 결측치가 있으면 작동하지 않으므로, 결측치를 처리하는 몇개의 함수를 만들어보겠습니다. 초반에 total_bedrooms에 결측치가 있는 것을 확인했으므로, 이를 처리해보겠습니다. 결측치를 처리하는 데에는 3가지 방법이 있습니다.
- 해당 구역을 제거하기.
- 해당 변수 전체를 제거하기.
- 결측치를 다른 값으로 대체하기 (0, 평균, 중위수 등).
위 방법은 각각 dropna(), drop(), fillna()를 이용해서 수행할 수 있습니다.
# 결측 데이터 중 5개만 가져옴
sample_incomplete_rows = housing[housing.isnull().any(axis=1)].head()
sample_incomplete_rows| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|
| 4629 | -118.30 | 34.07 | 18.0 | 3759.0 | NaN | 3296.0 | 1462.0 | 2.2708 | <1H OCEAN |
| 6068 | -117.86 | 34.01 | 16.0 | 4632.0 | NaN | 3038.0 | 727.0 | 5.1762 | <1H OCEAN |
| 17923 | -121.97 | 37.35 | 30.0 | 1955.0 | NaN | 999.0 | 386.0 | 4.6328 | <1H OCEAN |
| 13656 | -117.30 | 34.05 | 6.0 | 2155.0 | NaN | 1039.0 | 391.0 | 1.6675 | INLAND |
| 19252 | -122.79 | 38.48 | 7.0 | 6837.0 | NaN | 3468.0 | 1405.0 | 3.1662 | <1H OCEAN |
sample_incomplete_rows.dropna(subset=["total_bedrooms"]) # option 1: 해당 구역 제거| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity |
|---|
sample_incomplete_rows.drop("total_bedrooms", axis = 1) # option 2: 해당 열 제거| longitude | latitude | housing_median_age | total_rooms | population | households | median_income | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|
| 4629 | -118.30 | 34.07 | 18.0 | 3759.0 | 3296.0 | 1462.0 | 2.2708 | <1H OCEAN |
| 6068 | -117.86 | 34.01 | 16.0 | 4632.0 | 3038.0 | 727.0 | 5.1762 | <1H OCEAN |
| 17923 | -121.97 | 37.35 | 30.0 | 1955.0 | 999.0 | 386.0 | 4.6328 | <1H OCEAN |
| 13656 | -117.30 | 34.05 | 6.0 | 2155.0 | 1039.0 | 391.0 | 1.6675 | INLAND |
| 19252 | -122.79 | 38.48 | 7.0 | 6837.0 | 3468.0 | 1405.0 | 3.1662 | <1H OCEAN |
median = housing["total_bedrooms"].median()
sample_incomplete_rows["total_bedrooms"].fillna(median, inplace=True) # option 3: 중위수로 대체
sample_incomplete_rows| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|
| 4629 | -118.30 | 34.07 | 18.0 | 3759.0 | 433.0 | 3296.0 | 1462.0 | 2.2708 | <1H OCEAN |
| 6068 | -117.86 | 34.01 | 16.0 | 4632.0 | 433.0 | 3038.0 | 727.0 | 5.1762 | <1H OCEAN |
| 17923 | -121.97 | 37.35 | 30.0 | 1955.0 | 433.0 | 999.0 | 386.0 | 4.6328 | <1H OCEAN |
| 13656 | -117.30 | 34.05 | 6.0 | 2155.0 | 433.0 | 1039.0 | 391.0 | 1.6675 | INLAND |
| 19252 | -122.79 | 38.48 | 7.0 | 6837.0 | 433.0 | 3468.0 | 1405.0 | 3.1662 | <1H OCEAN |
Scikit-Learn은 SimpleImputer 클래스를 통해 결측치를 처리할 수 있다.
from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy="median")중위수는 숫자형 변수들에 대해서만 계산할 수 있기 때문에, 문자형 변수인 ocean_proximity를 제거한 데이터를 만듭니다.
housing_num = housing.drop('ocean_proximity', axis = 1)
imputer.fit(housing_num)SimpleImputer(add_indicator=False, copy=True, fill_value=None,
missing_values=nan, strategy='median', verbose=0)
imputer는 각 변수에 대한 중위수를 계산하고 그 결과를 statistics_ 인스턴스에 저장해 놓습니다.
imputer.statistics_array([-118.51 , 34.26 , 29. , 2119.5 , 433. , 1164. ,
408. , 3.5409])
housing_num.median().valuesarray([-118.51 , 34.26 , 29. , 2119.5 , 433. , 1164. ,
408. , 3.5409])
이제 우리는 이 학습된 imputer를 트레이닝 셋을 변환하는데 사용할 수 있습니다. 변환 결과가 NumPy array이기 때문에, Pandas DataFrame으로 변환해주겠습니다.
X = imputer.transform(housing_num)
housing_tr = pd.DataFrame(X, columns = housing_num.columns)Handling Text and Categorical Attributes
housing_cat = housing[['ocean_proximity']]
housing_cat.head(10)| ocean_proximity | |
|---|---|
| 17606 | <1H OCEAN |
| 18632 | <1H OCEAN |
| 14650 | NEAR OCEAN |
| 3230 | INLAND |
| 3555 | <1H OCEAN |
| 19480 | INLAND |
| 8879 | <1H OCEAN |
| 13685 | INLAND |
| 4937 | <1H OCEAN |
| 4861 | <1H OCEAN |
Scikit-Learn의 OrdinalEncoder 클래스를 이용하여 문자형 변수를 숫자형으로 변환하겠습니다.
from sklearn.preprocessing import OrdinalEncoderordinal_encoder = OrdinalEncoder()housing_cat_encoder = ordinal_encoder.fit_transform(housing_cat)
housing_cat_encoder[:10]array([[0.],
[0.],
[4.],
[1.],
[0.],
[1.],
[0.],
[1.],
[0.],
[0.]])
categories_ 인스턴스를 통해 카테고리 목록을 확인할 수 있습니다.
ordinal_encoder.categories_[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],
dtype=object)]
하지만 ocean_proximity열은 순서형 변수가 아니기 때문에, Scikit-Learn의 OneHotEncoder 클래스를 이용해서 one-hot encoding을 진행하겠습니다.
from sklearn.preprocessing import OneHotEncodercat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot<16512x5 sparse matrix of type '<class 'numpy.float64'>'
with 16512 stored elements in Compressed Sparse Row format>
결과가 SciPy spars matrix인데, 이는 몇천개의 범주가 있는 범주형 변수를 다룰 때 매우 유용하며, 일반적인 2D array처럼 사용할 수 있습니다. 하지만 Numpy array로의 변환을 원한다면 toarray() 함수를 사용하면 됩니다.
housing_cat_1hot.toarray()array([[1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1.],
...,
[0., 1., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.]])
Custom Transformers
자신만의 변환 함수를 작성하기 위해서는 클래스를 생성하고 fit(), transform(), fit_transform() 세가지 인스턴스를 적용하면 됩니다다. 마지막 인스턴스는 TransformerMixin을 베이스 클래스로 추가하면 얻을 수 있습니다. 또, BaseEstimator를 베이스 클래스로 추가한다면 hyperparameter 조정을 유용하게 할 수 있는 get_params(), set_params()의 메소드를 얻을 수 있습니다.
from sklearn.base import BaseEstimator, TransformerMixinrooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True):
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y = None):
return self
def transform(self, X, y = None):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, population_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)housing_extra_attribs = attr_adder.transform(housing.values)housing_extra_attribs = pd.DataFrame(
housing_extra_attribs,
columns=list(housing.columns)+["rooms_per_household", "population_per_household"],
index=housing.index)
housing_extra_attribs.head()| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | rooms_per_household | population_per_household | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 17606 | -121.89 | 37.29 | 38 | 1568 | 351 | 710 | 339 | 2.7042 | <1H OCEAN | 4.62537 | 2.0944 |
| 18632 | -121.93 | 37.05 | 14 | 679 | 108 | 306 | 113 | 6.4214 | <1H OCEAN | 6.00885 | 2.70796 |
| 14650 | -117.2 | 32.77 | 31 | 1952 | 471 | 936 | 462 | 2.8621 | NEAR OCEAN | 4.22511 | 2.02597 |
| 3230 | -119.61 | 36.31 | 25 | 1847 | 371 | 1460 | 353 | 1.8839 | INLAND | 5.23229 | 4.13598 |
| 3555 | -118.59 | 34.23 | 17 | 6592 | 1525 | 4459 | 1463 | 3.0347 | <1H OCEAN | 4.50581 | 3.04785 |
Feature Scaling
머신 러닝 알고리즘은 스케일이 매우 다른 수치형 변수들이 입력값으로 들어올 때 잘 작동하지 않습니다. housing data의 경우를 보면 총 방의수는 6 ~ 39,320의 값을 가지는 반면 중위 소득은 0~15의 값을 가집니다. 타겟 변수에 대해서는 보통 스케일링을 해주지 않아도 됩니다.
변수들이 동일한 스케일을 갖도록 하는 데에는 min-max scaling과 standardization 두가지 방법이 흔하게 쓰입니다.
Min-max 스케일링은 normalization이라고도 불리며, \(\frac{x - min(x)}{ max(x) - min(x)}\) 로 계산할 수 있습니다. 결과값은 0 ~ 1의 값을 가집니다. Scikit-Learn에서 제공해주는MinMaxScaler를 통해 이를 시행할 수 있으며, feature_range hyperparameter를 통해 0 ~ 1이 아닌 다른 범위를 갖도록 조정해 줄 수 있습니다.
Standardization은 좀 다릅니다. 먼저 변수에서 평균을 빼주고, 표준 편차로 나눠줍니다. 그 결과 변수는 평균 0, 표준편차 1을 갖게됩니다. min-max 스케일링과 다르게 standardization은 특정한 범위로 제한되지 않습니다. 이는 몇개의 알고리즘에서 문제가 될 수 도 있지만, 훨씬 이상치에 덜 민감합니다. Scikit-Learn에서 제공해주는 StandardScaler를 통해 이를 시행할 수 있습니다.
Transformation Pipelines
Scikit-Learn은 Pipeline을 통해 변환 과정을 쉽게 할 수 있도록 해줍니다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScalernum_pipeline = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler())
])housing_num_tr = num_pipeline.fit_transform(housing_num)Pipeline구조는 이름/함수 쌍의 리스트로 이루어져 있으며, 이름은 “__“를 포함하지 않고 유일하면 됩니다.
지금까지는 범주형 변수와 숫자형 변수를 따로 다뤄옸지만, 한 변환 함수로 모든 변수를 다룰 수 있다면 더 편리할 것입니다. 이런 목적으로 Scikit-Learn에서는 ColumnTransformer를 제공해주고 있습니다.
from sklearn.compose import ColumnTransformer # import ColumnTransformer class# 수치형, 범주형 변수명 리스트로 가져옴
num_attribs = list(housing_num)
cat_attribs = ['ocean_proximity']full_pipeline = ColumnTransformer([
('num', num_pipeline, num_attribs),
('cat', OneHotEncoder(), cat_attribs)
])housing_prepared = full_pipeline.fit_transform(housing)OneHotEncoder는 spars matrix를 반환해주지만, num_pipeline은 dense matrix를 반환해줍니다. 이 경우 ColumnTransformer는 최종 행렬의 density를 계산해서 주어진 threshold(기본값은 0.3)보다 작으면 spars matrix를 반환해주니다. 이 예제에서는 dense matrix가 반환됩니다.
Select and Train a Model
Training and Evaluating on the Training Set
먼저 선형 회귀 모형을 학습시켜보겠습니다.
from sklearn.linear_model import LinearRegressionlin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
학습이 다 됐습니다! 이제 트레이닝 셋에서 몇가지 인스턴스를 살펴보겠습니다.
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)print("Predictions:", lin_reg.predict(some_data_prepared))Predictions: [211944.80589799 321295.84907458 210851.33029021 62359.51850965
194954.19182968]
print("Lables:", list(some_labels))Lables: [286600.0, 340600.0, 196900.0, 46300.0, 254500.0]
예측이 정확하진 않지만 작동합니다. 이제 모든 학습 셋에서 선형모형의 RMSE를 Scikit-Learn의 mean_squared_error함수를 이용해서 측정해보겠습니다.
from sklearn.metrics import mean_squared_errorhousing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
lin_rmse68898.54780411992
모델이 과소추정됐음을 확인할 수 있습니다. 과소추정을 방지하기 위한 주요 방법으로는 더 강력한 모델을 선택하거나, 더 좋은 변수들에 대해서 알고리즘을 학습시키거나, 모델의 제약조건을 줄이는 방법이 있었습니다. 먼저 더 다양한 모델을 고려해보겠습니다.
DecisionTreeRegressor를 학습해보겠습니다. 이는 데이터내의 복잡한 비선형 관계를 찾을 수 있는 강력한 모델입니다.
from sklearn.tree import DecisionTreeRegressortree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)DecisionTreeRegressor(ccp_alpha=0.0, criterion='mse', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse0.0
이 모형은 너무 과대적합이 된 것 같습니다. 학습 셋의 일부분은 모델 학습에, 남은 일부분은 모델 검증에 사용해보겠습니다.
Better Evaluation Using Cross-Validation
train_test_split함수를 이용해서 학습 셋을 학습셋과 검증 셋으로 나누고, 학습 셋을 이용하여 모델 학습을 하고 검증 셋을 이용하여 모델 평가를 하겠습니다.
Scikit_Learn의 K-fold cross-validation 기능을 이용하겠습니다.
from sklearn.model_selection import cross_val_scorescores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring = "neg_mean_squared_error", cv = 10) # 10개의 fold를 생성하여 9개의 fold에 대해 학습하고 남은 fold에 대해 검증 => 10번 반복
tree_rmse_scores = np.sqrt(-scores)def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())display_scores(tree_rmse_scores)Scores: [68322.7680468 67344.1949072 71111.97297121 68232.88277112
69388.42266923 73551.92926776 66389.18496803 65965.04835166
72929.73570838 70972.37501955]
Mean: 69420.85146809198
Standard deviation: 2504.184049521599
이제 의사결정나무가 선형회귀모형보다 더 안 좋아 보입니다! 교차검증은 모델의 성능을 추정할 뿐만 아니라 추정치가 얼마나 정확한지도 제공해 줍니다.
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels,
scoring = "neg_mean_squared_error", cv = 10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)Scores: [67500.31361237 68404.48325957 68239.95757613 74813.56736728
68419.88576794 71632.92651865 65216.31837467 68702.06708289
71793.11060978 68131.30099374]
Mean: 69285.39311630058
Standard deviation: 2576.7108344336148
의사결정나무가 너무 과적합이 돼서 선형회귀모형보다 나쁜 성능을 갖는 것을 확인할 수 있습니다.
마지막으로 RandomForestRegressor를 시도해보겠습니다. 랜덤포레스트는 많은 의사결정나무를 random subset에 대해 학습하고, 그것들의 예측값을 평균냅니다. 많은 모형들을 합쳐서 모형을 세우는 것을 Ensemble Learning이라고 합니다.
from sklearn.ensemble import RandomForestRegressorforest_reg = RandomForestRegressor()
forest_reg.fit(housing_prepared, housing_labels)
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
forest_rmse18394.124106167335
forest_scores = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring = "neg_mean_squared_error", cv = 10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)Scores: [48683.58219131 46623.27699751 49011.64266635 51534.49201646
48653.03431624 53399.64129095 48443.68188694 47347.67800381
52741.38831191 49513.82099873]
Mean: 49595.223868020454
Standard deviation: 2130.9314460756927
와! 훨씬 좋아 보입니다. 하지만 학습 셋에 대한 점수는 여전히 검증 셋에 대한 점수보다 훨씬 낮은 모습을 볼 수 있는데, 이는 모형이 여전히 학습 셋에 대해 과적합 됐다는 것을 의미합니다. 과적합을 막기 위한 방법은 모형을 단순화 하거나, 제한을 두거나, 더 많은 학습 데이터를 얻는 것입니다.
Fine-Tune Your Model
Grid Search
모델 조정을 위한 하나의 방법으로는 hyperparameter를 수동으로 조정해보며, 가장 좋은 조합을 찾는 것입니다. 이를 위한 대안으로 Scikit-Learn은 GridSearchCV르르 제공해줍니다. 우리는 이제 수종으로 조정해 볼 필요없이 어떤 hyperparameter를 시험해보고 싶은지, 어떤 스코어를 사용할 건지, 교차검증을 사용할건지에 대해서만 선언해주면 됩니다.
from sklearn.model_selection import GridSearchCVparam_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]}, # 3X4 조합 시도해 봐라
{'bootstrap': [False], 'n_estimators': [ 3, 10], 'max_features': [2, 3, 4]} # 1X2X3 조합 시도해 봐라
] # 따라서 총 18개 조합을 시험해 봄forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv = 5, # 18개 조합을 5번 (총 90번)
scoring = "neg_mean_squared_error",
return_train_score = True)
grid_search.fit(housing_prepared, housing_labels)GridSearchCV(cv=5, error_score=nan,
estimator=RandomForestRegressor(bootstrap=True, ccp_alpha=0.0,
criterion='mse', max_depth=None,
max_features='auto',
max_leaf_nodes=None,
max_samples=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=100, n_jobs=None,
oob_score=False, random_state=None,
verbose=0, warm_start=False),
iid='deprecated', n_jobs=None,
param_grid=[{'max_features': [2, 4, 6, 8],
'n_estimators': [3, 10, 30]},
{'bootstrap': [False], 'max_features': [2, 3, 4],
'n_estimators': [3, 10]}],
pre_dispatch='2*n_jobs', refit=True, return_train_score=True,
scoring='neg_mean_squared_error', verbose=0)
grid_search.best_params_ # 최선의 모수 조합{'max_features': 8, 'n_estimators': 30}
grid_search.best_estimator_ # 최선의 모형RandomForestRegressor(bootstrap=True, ccp_alpha=0.0, criterion='mse',
max_depth=None, max_features=8, max_leaf_nodes=None,
max_samples=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=30, n_jobs=None, oob_score=False,
random_state=None, verbose=0, warm_start=False)
# 조합별로 스코어 확인하기
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)63150.43821664293 {'max_features': 2, 'n_estimators': 3}
55365.90761626427 {'max_features': 2, 'n_estimators': 10}
52495.50683328804 {'max_features': 2, 'n_estimators': 30}
60090.743499511824 {'max_features': 4, 'n_estimators': 3}
52448.798224728984 {'max_features': 4, 'n_estimators': 10}
50190.981478720816 {'max_features': 4, 'n_estimators': 30}
59229.50515940641 {'max_features': 6, 'n_estimators': 3}
51934.46906482807 {'max_features': 6, 'n_estimators': 10}
50039.22771052925 {'max_features': 6, 'n_estimators': 30}
57727.65754412416 {'max_features': 8, 'n_estimators': 3}
51265.14978086802 {'max_features': 8, 'n_estimators': 10}
49746.36471858636 {'max_features': 8, 'n_estimators': 30}
61824.30384486343 {'bootstrap': False, 'max_features': 2, 'n_estimators': 3}
54206.90549539195 {'bootstrap': False, 'max_features': 2, 'n_estimators': 10}
61124.16472302618 {'bootstrap': False, 'max_features': 3, 'n_estimators': 3}
52381.58278006336 {'bootstrap': False, 'max_features': 3, 'n_estimators': 10}
58449.252841001064 {'bootstrap': False, 'max_features': 4, 'n_estimators': 3}
51460.00161462604 {'bootstrap': False, 'max_features': 4, 'n_estimators': 10}
Randomized Search
hyperparameter search space가 크다면 RandomizedSearchCV를 사용하는게 더 선호됩니다. 이는 모든 가능한 조합을 시도해 보는 대신, 각 iteration마다 hyperparameter를 random하게 선태갛여 조합해서 모형을 평가합니다. 이 접근 방법에는 두가지 장점이 있습니다.
- 만약 1,000 iteration을 시행하기로 한다면 각 hyperparameter에 대해 1,000개의 다른 값을 시험해 볼 수 있습니다.
- 반복 횟수를 조정함으로서 hyperparameter 탐색에 사용할 컴퓨팅 시간을 조정할 수 있습니다.
Ensembel Methods
시스템 조정을 위한 다른 방법은 성능이 좋은 모델 몇개를 합치는 것입니다. 이 그룹 (앙상블)은 특히 개별 모형이 서로 다른 유형의 에러를 가질 때, 각 개별 모델보다 보통 더 좋은 성능을 냅니다.
Analyze the Best Models and Their Errors
가장 좋은 모델을 탐색하다 보면 문제에 대한 좋은 인사이트를 종종 얻을 수 있습니다. 예를 들어, RandomForestRegressor는 정확한 예측을 만드는 데에 각 변수의 상대적인 중요도를 제시해 줄 수 있습니다.
feature_importances = grid_search.best_estimator_.feature_importances_
feature_importancesarray([7.32120557e-02, 6.68346781e-02, 3.97850051e-02, 1.53916012e-02,
1.52789359e-02, 1.50822701e-02, 1.40855345e-02, 3.62067657e-01,
3.62950942e-02, 6.98189731e-02, 1.20196159e-01, 4.51046693e-03,
1.63280903e-01, 8.13436743e-05, 1.49618141e-03, 2.58314103e-03])
중요도를 변수명과 함께 나타내겠습니다.
extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"]
cat_encoder = full_pipeline.named_transformers_['cat']
cat_one_hot_attribs = list(cat_encoder.categories_[0]) # 카테고리 이름 가져오기
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse = True) # reverse : 내림차순 정렬[(0.3620676573166388, 'median_income'),
(0.16328090303414522, 'INLAND'),
(0.12019615871994084, 'bedrooms_per_room'),
(0.07321205566930188, 'longitude'),
(0.06981897311263754, 'pop_per_hhold'),
(0.06683467813511235, 'latitude'),
(0.03978500505044002, 'housing_median_age'),
(0.03629509424762905, 'rooms_per_hhold'),
(0.015391601198070742, 'total_rooms'),
(0.015278935883605725, 'total_bedrooms'),
(0.01508227006055201, 'population'),
(0.014085534524203358, 'households'),
(0.00451046692513494, '<1H OCEAN'),
(0.0025831410344444245, 'NEAR OCEAN'),
(0.001496181413867298, 'NEAR BAY'),
(8.134367427586688e-05, 'ISLAND')]
이 정보를 보면 덜 중요해보이는 변수들을 제거하고 싶을수도 있습니다. 예를 들어, ocean_proximity 카테고리에서는 INLAND를 제외한 나머지 카테고리는 중요해 보이지 않습니다.
Evaluate Your System on the Test Set
이제 최종 모형을 테스트 셋으로 평가해 보겠습니다.
final_model = grid_search.best_estimator_X_test = strat_test_set.drop('median_house_value', axis = 1)
y_test = strat_test_set['median_house_value'].copy()X_test_prepared = full_pipeline.transform(X_test)final_prediction = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_prediction)
final_rmse = np.sqrt(final_mse)final_rmse47994.65006717922
에러에 대한 신뢰구간을 얻기 위해서는 scipy.stats.t.interval()을 사용하면 됩니다.
from scipy import statsconfidence = 0.95
squared_errors = (final_prediction - y_test) **2
np.sqrt(stats.t.interval(confidence, len(squared_errors)-1,
loc = squared_errors.mean(),
scale = stats.sem(squared_errors))) # 평균의 표준 에러 계산array([46010.97510772, 49899.52945449])
Launch, Monitor, and Maintain Your System
프로덕션 입력 데이터 소스를 시스템에 연결하고 테스트를 작성하여 솔루션을 생산할 수 있도록 준비해야 합니다.
또한, 모니터링 코드를 작성하여 시스템의 성능을 정기적으로 확인하고, 성능이 떨어질 때 경고를 할 수 있도록 해야합니다. 시스템의 갑작스러운 중단 뿐만 아니라, 성능 저하를 알아채는 것도 중요합니다. 이는 모형이 새로운 데이터에 대해 정기적으로 학습하지 않는 이상, 데이터가 새로 들어올 수록 모형이 서서히 악화되는 경향이 있기 때문에 매우 흔하게 일어납니다.
시스템의 성능을 평가하는 건 시스템의 예측치를 수집하고 평가하는 것을 필요로 합니다. 이는 보통 사람이 분석해야 하고, 분석가는 분야의 전문가나 크라우드소싱 플랫폼 종사자여야 합니다. 어느 쪽이든 인적 평가 파이프라인을 시스템에 연결해야 합니다.
또, 시스템의 입력 데이터 품질을 평가해야 합니다. 가끔 나쁜 품질의 신호 때문에 성능이 저하되기도 하는데, 경고가 뜰 정도로 성능이 저하되려면 꽤 시간이 걸리므로, 만약 시스템의 입력값을 확인한다면 더 빨리 알아챌 수 있을겁니다. 특히 입력값의 모니터링은 온라인 학습 시스템에서 중요합니다.
마지막으로, 새로운 데이터를 사용하여 모델을 정기적으로 학습시켜야 하며, 이 과정을 최대한 자동화해야 합니다. 그렇지 않으면 (최선을 다해야) 6개월마다 모델을 수정할 가능성이 매우 높으며, 시간이 지남에 따라 시스템 성능이 크게 변동할 수 있습니다. 시스템이 온라인 학습 시스템인 경우 이전에 작동하던 상태로 쉽게 돌아갈 수 있도록 정기적으로 상태 스냅샷을 저장해야 합니다.