Boosting
부스팅은 무작위로 선택하는 것 보다 약간 가능성이 높은 분류기 (weak classifier)를 결합시켜서 강한 분류기를 만들어 내는 것을 말합니다.
배깅과의 가장 큰 차이점은 부스팅 기법은 새로운 분류기를 학습할 때 마다 이전의 결과를 참조하여 Weighted sample을 이용한다는 점 입니다. (배깅의 모델 학습은 병렬 형태)
즉, 처음에는 모든 샘플에 동일한 가중치를 적용 (1/n)하여 분류기를 학습합니다. 그 이후부터는 이전 분류기가 잘못 분류한 샘플들에 대해 더 큰 가중치를 주어서 분류기를 학습합니다. 여기서 주의할 점은 마지막 모델이 아닌 학습에 이용된 모든 분류기들의 앙상블이 최종 모델이 된다는 점 입니다. 이를 그림으로 나타내면 아래와 같습니다.
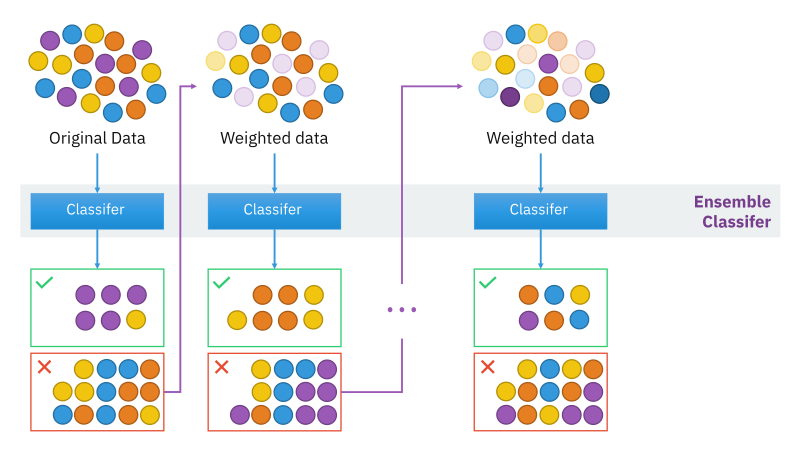
부스팅의 Weak classifier에는 일반적으로 의사결정나무모형을 사용하고, 부스팅은 과적합에 강하다는 장점을 가지고 있지만, 분류 결과에 대한 해석이불가능하고, Noise가 많은 데이터에서는 별로 좋은 결과를 얻지 못할 수 있습니다.
여기서는 일단 수식을 최대한 제외하고 부스팅 기법들을 소개하겠습니다.
AdaBoost (Adaptive Boosting)
에이다부스트는 위에 설명한 부스팅 기법을 발전시킨 알고리즘입니다. 기존 부스팅 기법은 최종 모델을 개별 분류기의 단순 앙상블로 만들어 냈지만, 에이다부스트는 학습에 이용된 개별 분류기에 서로 다른 가중치를 주어서 최종 분류기를 만들어 냅니다.
약한 분류기의 가중치가 고려된 오류율을 \(e_m\)이라 하면, 각 개별 분류기에 적용되는 가중치는 \(\alpha_m = L\frac{1}{2} \ln \frac{1-e_m}{e_m}\)으로 표현할 수 있습니다. 보통 L = 1 이지만, 코딩시에는 L값을 조절하여 학습시킬 수 있습니다.
파이썬에서 에이다부스트를 사용하는 방법은 아래와 같습니다.
from sklearn.ensemble import AdaBoostClassifier
clf = AdaboostClassifier(base_estimator = DecisionTreeClassifier(max_Depth = 1), # Weak classifier
n_estimators = 50, # 몇개의 분류기를 학습할 것 인지
learning_rate = 1) # 위에서 설명한 L
clf.fit(X, y)GBM (Gradient Boosting Method)
위에서 살펴본 AdaBoost는 잘못 분류된 점을 이용하여 약분류기 학습의 가중치를 결정하였다면, GBM은 Gradient Descent 기법을 이용하여 손실함수를 최소화하는 방향으로 학습을 합니다.
AdaBoost에서는 Exponential error function을 사용했지만, GBM에서는 내가 원하는 Loss function을 사용할 수 있다는 장점이 있습니다.
파이썬에서 GBM을 사용하는 방법은 아래와 같습니다. GBM에는 상당히 많은 모수들이 있기 때문에, 모수에 대한 설명을 링크해두겠습니다.
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier(loss = 'deviance',
learning_rate = 0.1,
n_estimators = 100,
max_depth = 3)
gbc.fit(X, y)코드에서도 AdaBoost와 달리 loss모수를 통해 손실 함수를 직접 조절할 수 있는 것을 확인할 수 있습니다. 여기서 위에 쓰인 ‘deviance’는 확률 값이 나오는 로지스틱 회귀모형의 손실함수를 의미하며, ‘exponential’은 Adaboost 모형과 동일한 exponential error function을 의미합니다.
XGBoost (Extreme Gradient Boosting)
XGBoost 또한 Gradient Boosting에 기반을 두고 있습니다. 하지만 XGBoost는 CART기반의 트리를 사용하고, 손실함수 뿐만 아니라 모형 복잡도까지 고려하고 있는 기법입니다. 그만큼 XGBoost또한 많은 양의 모수들을 필요로 합니다. 모수에 대한 자세한 설명은 역시 링크를 찹조하기 바랍니다.
자주 쓰이는 몇 가지 모수에 대해서만 간단하게 설명해보겠습니다.
eta: learning rate [0, 1], 값이 작을 수록 이전 단계의 결과물을 적게 반영하게 됩니다.gamma: min split loss [0, \(\infty\)], 값이 클 수록 가지를 적게 만듭니다.max_depth: 의사결정나무 깊이의 한도
XGBoost를 사용하려면 parameter tuning이 필수적입니다. 이에 대해 자세하게 나와있는 게시물을 링크해두겠습니다.